Привет, опытные арбитраны! Неопытным тоже привет!
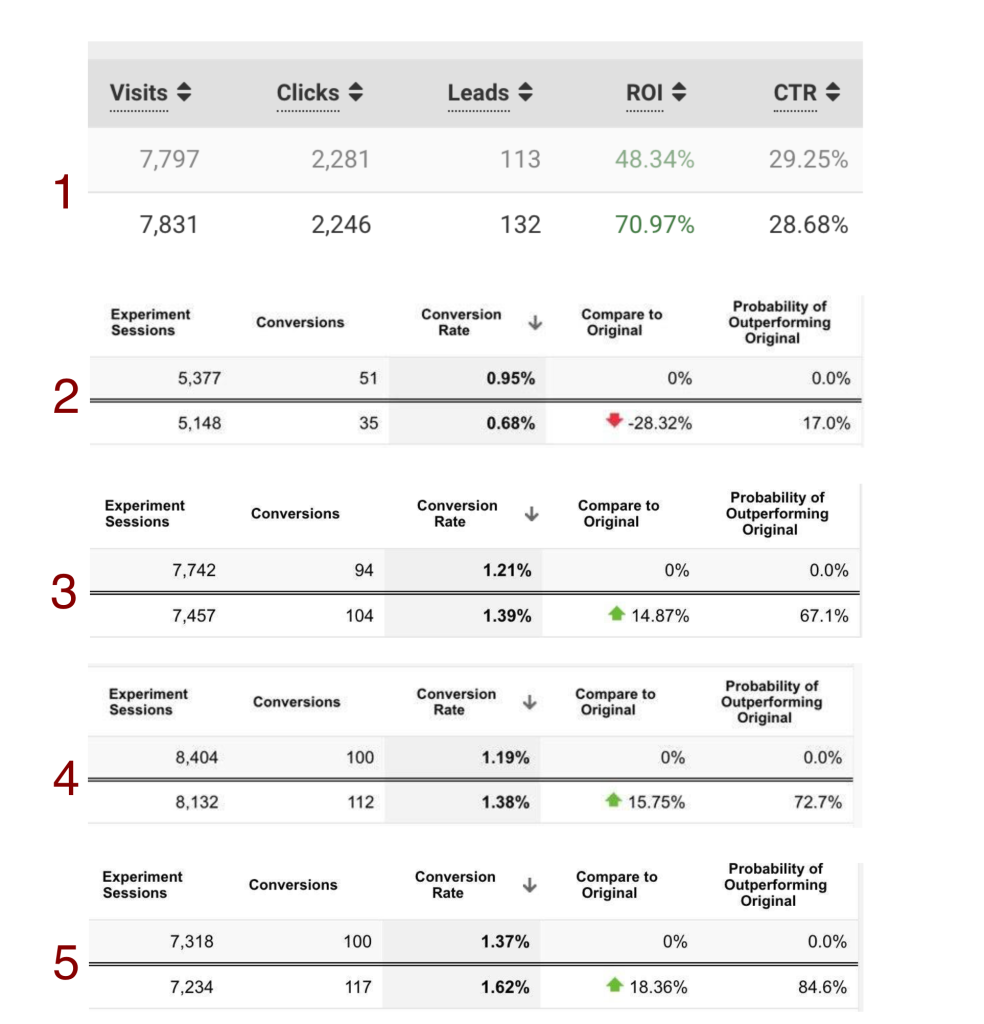
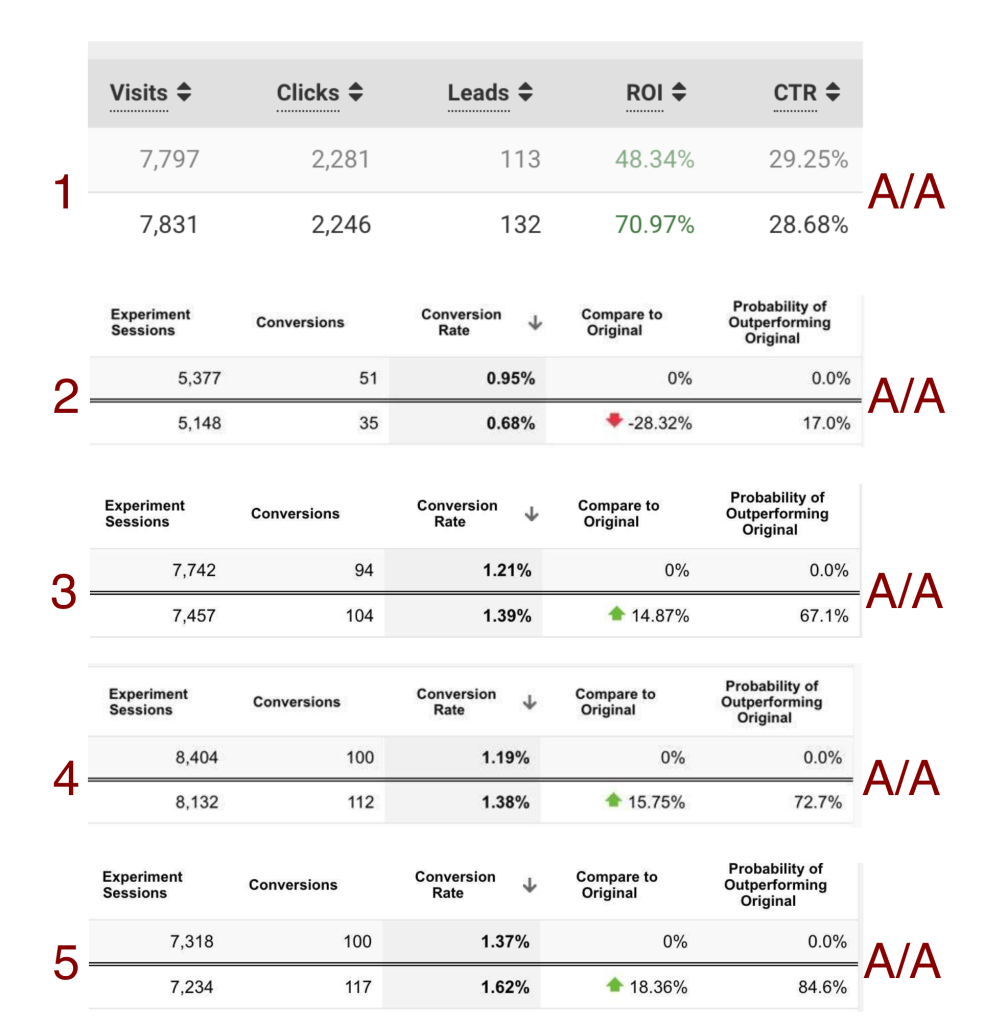
Сможете угадать, где на скринах бесполезный AA, а где честный AB тест? Где победитель очевиден, а где надо еще полить? Ответ — в конце поста.
tldr;
A/B-тесты часто проводятся неправильно из-за когнитивных искажений, ограничений инструментов и ограничений самого метода. Решения на основе таких тестов низкого качества. A/A-тесты — это простой инструмент, который повышает качество решений на базе A/B-тестов.
—
Недавно я помогал выстроить тестирование лендов. Не первый раз вижу ситуацию, когда A/B-тесты проходят случайно, включили, не собрали достаточно данных, решили, что достаточно, выключили. Как результат — решения тоже случайные. Как справиться? Читайте.
Что за A/B тестирование?
Про A/B-тесты вы, вероятно, знаете, но я все равно расскажу. A/B-тесты, они же сплит-тесты, нужны для того, чтобы на живом трафике сравнить, какой из вариантов лучше. В арбитраже трафа речь обычно идет про тесты лендов (целевых страниц) или офферов, иногда объявлений, но с ними своя атмосфера. В других отраслях это может быть что угодно с целевой метрикой, которую можно сравнивать: тесты пейволов, чекаутов, иконок, онбордингов, you name it. Надо отметить, что A/B тесты — инструмент с кучей ограничений. Арбитраж — одна из немногих отраслей где они относительно хорошо применимы, так как воронки обычно очень прямолинейные.
Целевая метрика в арбитраже — выручка, прибыль или их производные. Можно посматривать на другие метрики, например, иногда имеет смысл смотреть на CTR, но основная метрика почти всегда про деньги: revenue в чистом виде, profit, ROI, EPV — любая подойдет.
Зачем нужны A/B-тесты и в чем сложность?
Затем что арбитраж — это во многом про постоянные эксперименты. Эксперименты надо делать правильно, иначе решения ваши будут — говно. A/B — это один из инструментов, чтобы не просрать все гипотезы.
Провести правильный A/B-тест не так просто. Есть пачка вопросов, которые не такие простые, как может показаться: что считать гипотезой, вариантом и целевой метрикой, как сравнивать варианты, как влияют условия покупки трафика, есть ли другие скрытые факторы.
В этом посте я сфокусируюсь на вопросе: как понять, сколько трафика нужно отправить, чтобы эксперимент был валидным.
Есть инструменты, типа калькулятора статистической значимости, которые вроде бы позволяют это решить, но нет. Калькулятор стат-значимости — ограниченный инструмент с кучей недостатков и он требует понимания, как и когда его использовать. Есть и другие инструменты, типа байесовских тестов или CUPED (похоже, что это повод написать отдельный пост). Они тоже не панацея и требуют достаточно сложного проектирования и проведения эксперимента. Есть многорукие бандиты, вот и Желтый пишет про них. В одном из моих самописных трекеров я использовал многоруких бандитов, что-то из серии UCB и в целом оно работает, при этом, если отдавать их баерам, то возникает другая проблема — баеры не ждут, баеры считают, что такой алгоритм недостаточно агрессивный и начинают вмешиваться руками. Пробовал я и всякие классические ML-истории, типа SVM — это интересный инструмент, но очень со своей атмосферой. Плюс не у всех есть возможность это вкрутить самостоятельно в трекинговые решения. Что не отменяет того факта, что это вполне себе решение.
Если говорить баеру, что принимать решение на 20-30 конверсиях — плохая идея, то баер не верит. Не верит он, если показывать калькуляторы стат-значимости, последовательные и байесовские тесты. Не верит и все тут. Ну вот же, все видно: по 500 кликов на ленд, тут 17 конверсий, а тут 11. Понятно же, кто победитель, чего ты пристал, ну. Обычная история и в партнерском маркетинге, и в екоме, и в инсталлах, и внутри продуктов.
Почему так происходит? Потому что random — это страшная сила с одной стороны, а с другой стороны человек интуитивно не умеет в вероятности, у человека весь букет когнитивных искажений. Я, наверное, про это напишу отдельный пост, а сейчас идем дальше. Параллельно не забываем, что надо почитать Канемана, Талеба и немного Юдковского (до того, как он ушел в AI-алармизм).
Что за A/A тесты?
Хорошо, с A/B все понятно (понятно же?) — инструмент нужный, непростой, хоть и кажется простым.
А что такое A/A-тест и зачем это надо?
A/A-тест — это когда вы ставите в тест два абсолютно и безнадежно идентичных варианта. Два одинаковых лендинга, два одинаковых оффера. Обзываете их по-разному, чтобы отличить в стате. Поставили, что дальше? Ждем, что варианты покажут одинаковый результат. Дальше происходит удивление. Например, суммарно 200 конверсий и расхождение 20%, на одинаковых вариантах, как же так?
Вот так: случайность сильна, выборка небольшая, трафик неоднородный.
Кроме этого в таких тестах, надо думать об офферах. Круится за лендами в сплите еще 3 оффера — возможно у вас уже A/B/C/D/E/F тест.
Расхождения все равно будут почти всегда, нормально, если у вас расхождение 3-5% на А/А-тесте на сотнях конверсий, если расхождение больше — что-то идет не так.
Зачем нужны А/А тесты?
Хорошо, воткнули А/А, а чего взамен?
Имеем ситуацию:
— A/B-тесты — сложный инструмент, который кажется простым
— Довольно часто мы не осознаем силу случайности и подвержены когнитивным искажениям
— Тестировать надо правильно, а не как всегда
Если столкнулись с такой ситуацией — достаем A/A-тест. A/A-тесты, при правильном применении, неплохо показывают, что происходит с экспериментом и когда эксперимент становится валидным.
Важно: надо на старте исключить ситуацию, когда вы смотрите в стату и выбираете момент, в котором эксперимент (случайно) сошелся. Разница может вырасти опять. Например, A/A-тест может показать близкие показатели конверсии на небольшом объеме трафика (десятки конверсий), но если подождать еще несколько десятков, то результаты могут разойтись.
Такие тесты — это практический способ, без магии, регистрации и смс, получить достаточно надежный эксперимент.
Плюсы:
— легко сделать технически — достаточно поставить среди тестов еще и А/А
— практические и неоспоримые результаты, то есть пока у вас два А варианта не сошлись, очевидно, что данных по варианту B недостаточно
— позволяет поймать косяки с трекингом или скрытые факторы, которые влияют на конверсию
Минусы:
— Надо контролировать эксперимент (и себя) на ранних этапах. Создаем правила минимального количества конверсий до принятия решений.
— Нужно больше трафика на тест.
Что делать на практике
На практике как обычно — it depends. Всегда надо думать над своими экспериментами. Отправная точка:
— Хороший тест — это время и объем. Этот факт надо принять.
— Перед A/B тестом надо понять базовый уровень. Сделайте 2-3 A/A-теста в самом начале: по 200 конверсий на вариант. Меньше не надо. Почему 200? Это практически полученное значение, больше — лучше. Ждем расхождение не больше 5%. У вас вместо 5% будет то расхождение, которое на A/B-тестах вы сочтете допустимым. Если на этом диапазоне расхождение больше, то надо разобраться, нет ли технических ошибок, не нет ли скрытой вариативность, которая превращает A/A тест в A/B или A/B/C/D, искать другие причины.
— Ставим A/A/B тест в равном соотношении. Можно ставить неравное, но это усложнит контроль:
— Если на B-варианте конверсий нет совсем, а на AA уже нападало 10-15 — проверяем техническую часть и льем дальше.
— Конверсий около 50 и разница в 2-3 раза между вариантами — пограничный вариант. Данных явно мало, но варианты отличаются сильно. Имеет смысл перепроверить техничку и другие источники загрязнений и полить еще 10-15 конверсий. Если расхождение остается прежним — останавливать.
— Конверсий меньше 100 на каждый вариант И вариант B хуже на 50% — останавливаем
— Ухудшающий результат можно останавливать раньше, улучшающий валидировать еще несколько дней.
— Новое гео, новый продукт, новый оффер, новый подход — это новый тест. Результаты прошлых тестов, по моему опыту, чаще пригодны, чем нет, но никогда не знаешь заранее. Здравый смысл в помощь.
— Тест должен проходить в одинаковых условиях: варианты должны тестироваться одновременно, на одном потоке трафика, на одной технической платформе и т.д. Последовательное подключение вариантов — плохой тест. У вас изменится очень много условий, в эксперимент не будет смысла.
— Тест длится хотя бы неделю, чтобы учесть дневную и недельную сезонность
— После завершения теста правильно держать A/A варианты всегда для health-check. Тогда вы сможете понять, если что-то пошло не так технически или появилась новая вариативность.
Чеклист А/А/B-тестов:
— A/A-тесты для базового уровня: 2-3 АА-теста, 200 конверсий на вариант, расхождение < 5%
— А/А/B-тесты в равном соотношении:
— 10-15 конверсий на A и нет конверсий на B — проверяем техничку и льем дальше
— 50 конверсий, разница 2-3 раза — проверяем техничку, льем 10-15 конверсий и останавливаем
— 100 конверсий, разница больше 50% — надо останавливать
— Новые гео, продукт, оффер — новый тест
— Ухудшающий — останавливаем, улучшающий проверяем на x2-x3
— Тест проходит в одинаковых условиях
— Желательно длится неделю
— Варианты ставятся одновременно
— Оставляем A/A на основе победителя
Почему A/A-тесты не сходятся я напишу отдельно.
Важно: инструмент — не 100% гарантия качественного теста. Это быстрый и практически применимый механизм, наглядно повышает качество A/B-теста, но не отменяет качественного планирования эксперимента.
Теперь ответ на вопрос в начале поста: все тесты — A/A, там нет ни одного A/B. С A/B разберетесь теперь сами.
Закончить чтение поста с ощущением некоторого недоверия — это ок. Не верьте мне, пробуйте сами.